
分かりやすいデータモデルを作る3つの配置ルール
データモデルの表記法はいくつかありますが、誰もが理解できることに着目したルールはあまりありません。エンティティ数が増え、データ構造が複雑になると、リレーションシップが錯綜し、解釈にかなりの労力を要します。そのため、本来データモデルは、業務を理解したり、DB設計に繋げたりするための、皆で共有すべき重要な成果物であるにも関わらず、データモデル作成者だけが理解できるものでしょ、と嫌煙されがちです。そこで今回は、データモデルを分かりやすくすることに着目したルールと、そのメリットをご紹介します。
なお、本ブログでご紹介する3つのルールは、『データ中心システムの概念データモデル』(著者:故 椿正明、発行年:1997年)で紹介されている、データモデルのレイアウト規則を参考にしました。本書は、発行から25年以上が経過した今でも通用する、データモデリングの理論について丁寧に解説されていますので、ご興味のある方はぜひ一読ください。
分かりやすいデータモデルを作るための3つの配置ルール
まず、下図のデータモデル(図1)をご覧ください。リレーションシップが錯綜し、エンティティ間の関係性や全体像が理解しにくいという印象を持つ方が多いでしょう。
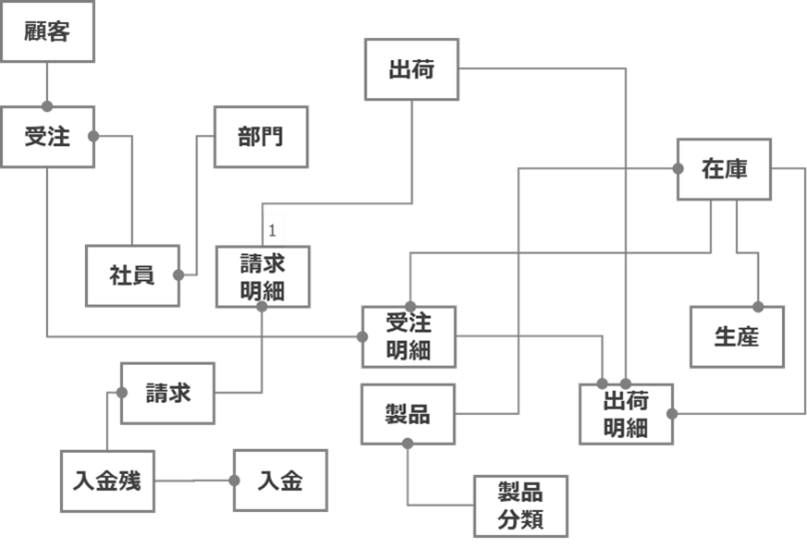
(属性は省略し、エンティティ名のみ表示)
このデータモデルを分かりやすくするために、以下3つのルールを適用してみます。
ルール1.粒度の違いに着目してエンティティを配置する
次のルールを適用して、エンティティの配置を整えます。
・粒度が異なる2つのエンティティでは、粒度が粗いエンティティを上側、細かいエンティティを下側に配置する
・粒度が同じ2つのエンティティであれば、同じ高さに揃える
こうすることで、エンティティの配置からデータの粒度の違いや関係性を読み取ることができるようになります。粒度に着目してエンティティを配置する内容は、こちらのブログ(粒度・配置に留意して分かり易いデータモデルを目指そう!)にも書かれていますのでご参照ください。
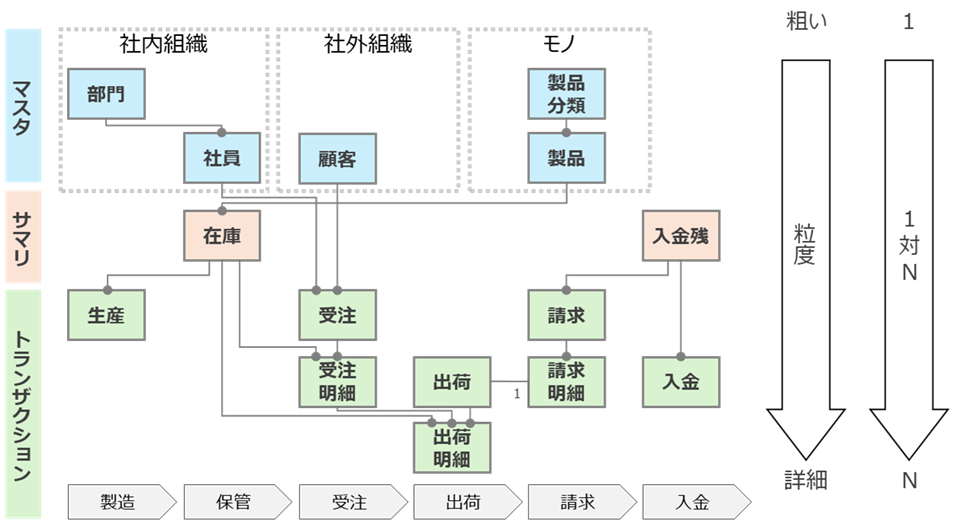
ルール2.マスタ→サマリ→トランザクションの順番で、上から下へ向かって配置する
ルール1に従うと、自然とマスタは上段、トランザクションは下段に配置されます。これは、マスタはトランザクションから参照されるため、常に1対多の関係となるからです。また、サマリデータ(月別売上や在庫など)は、トランザクションデータを集計して作成するため、サマリは、トランザクションの上に配置されます。その結果、上から下へ向かってマスタ→サマリ→トランザクションの順に配置されます。
ルール3.マスタはグルーピングし、トランザクションは時系列で配置する
マスタは、似たエンティティをグルーピングして配置すると、どのような種類のマスタがあるのかが分かりやすくなります。例えば、「社内組織」「社外組織」「モノ(製品・部品)」「その他」にグルーピングします。トランザクションやサマリは、業務や時間軸の流れに沿って左から右に向かってエンティティを配置します。こうすることで、業務の流れに沿って、データ構造を把握することができます。
上記3つのルールを適用すると、下図のようなデータモデル(図2)になります。エンティティの配置が整理されることで、データ間の関係性や全体像が分かりやすくなります。
配置ルールに従うことによる3つのメリット
次に、データモデルが分かりやすくなると、どのようなメリットがあるのかご紹介します。
メリット1.DB設計者が、エンティティの抜け漏れに気付く
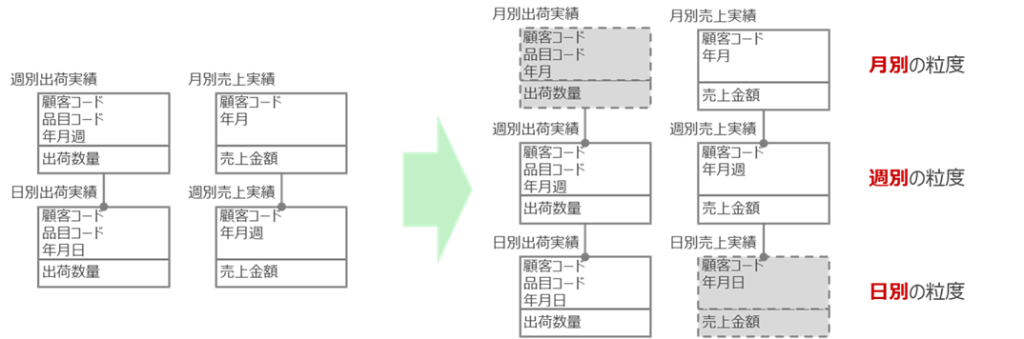
例えば、下図のデータモデル(図3)をご覧ください。左の絵でも、集計粒度の粗いエンティティが上、細かいエンティティが下になるように配置されていますが、右の絵では、さらに月別、週別、日別といった集計粒度に着目して、集計粒度が同じエンティティの高さを揃えて配置しています。このようにエンティティを配置することで、DB設計者は、月別や日別の粒度のエンティティが欠けていることに気付き、業務側に要件を確認するなど、設計の抜け漏れを防ぐことができるようになります。
メリット2.データガバナンス担当者による、データモデルのレビュが容易なる
データモデルが分かりやすくなれば、データガバナンス担当者は、データの構造や関係性を容易に把握できるようになり、レビュを効率的に行えるようになります。さらに、重要な指摘事項(例えば、エンタープライズ・データモデルで定められているデータ構造に従っているか、ビジネス要件や利活用要件に適したデータ構造になっているか、など)を見逃すことも少なくなります。データガバナンスのルールを遵守し、品質の高いデータモデルを作成するためには、データガバナンス担当者によるレビュは不可欠であり、データモデルが分かりやすくなることでレビュ精度を高めることができます。
メリット3.データ利活用者が、データを理解しやすくなる
データモデルは、DB設計の成果物に留まらず、最近ではデータ利活用者がデータの所在やデータの関係性を理解するための「データの地図」としての役割も果たすようになりました。データモデルが分かりやすければ、何らかの分析をするためにはどのデータを組み合わせてみるとよいのか、売上などを集計するためはどのトランザクションデータを使うとよいのか、といった疑問が湧いた際に、迷うことなく対象となるデータをデータモデルから見つけ出すことができます。しかし、データモデルが分かりにくいと、必要なデータを見つけるのに時間がかかったり、必要なデータに辿り着けなかったりするため、他の人に確認するなどの手間がかかります。データモデルが分かりやすくなることで、データ利活用者は必要なデータをすぐに特定でき、その結果、本来行うべき業務に時間を割けるようになります。
国家試験でもエンティティ配置に工夫あり
毎年秋に実施される「データベーススペシャリスト試験」では、概念データモデルに関する問題が出題されます。令和6年度の問題にある概念データモデルは、下図のとおりです。(引用元:IPA令和6年度DBスペシャリスト試験過去問)
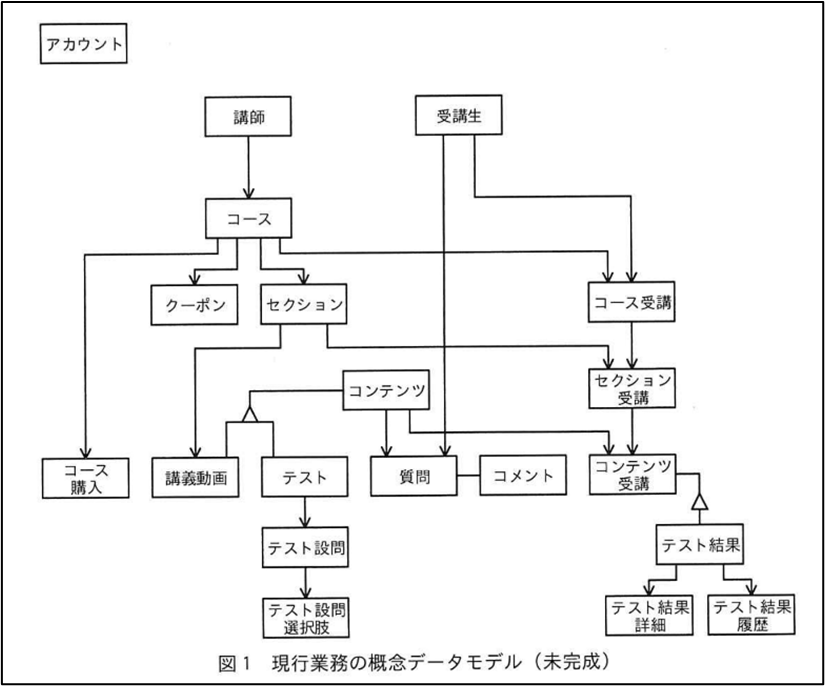
これまでご紹介した3つの配置ルールに概ね沿って配置されています。受験者が短時間でデータモデルを理解できるよう、工夫されているのだと考えられます。これにより、受験者は、データモデルをどう修正・拡張するかという設問への解答に集中できるのでしょう。
少しの意識で、大きな効果を
データモデルの配置ルールは世の中的にはあまり浸透していないようですが、少し意識するだけで様々なメリットが得られます。これからデータモデルを作成する際は、面倒がらずにぜひこの配置ルールを適用して、その効果を実感いただければ幸いです。弊社では、データモデリングの教育コースを提供しており、配置ルールの話もお伝えしております。興味のある方はぜひご検討ください。
https://metafind.jp/education/data_management_academy/data_modeling/

