粒度・配置に留意して分かり易いデータモデルを目指そう!

●現状把握に有効なデータモデル
データ利活用やシステム再構築の際、複数のシステムで同じ意味のエンティティが管理されているような場合には、エンティティの統合を検討します。これにはデータ構造を図に示すデータモデルが有効です。例えば、現状のシステムではどのようにデータが管理されているのかを図で表現しておくと、空中戦になることなく、関係者と認識を合わせながら、どこをどう統合していくのか検討することが可能になります。ですが、せっかく作成したモデルも見にくいと効果半減です。正確で分かり易いデータモデルを作成するポイントをいくつかご紹介します。
●ポイント1:粒度の違いに着目する
名称が似ていて、同じような対象を管理しているように見えるテーブルでも、分析してみると、実は登録されているデータの粒度が異なっていたということがあります。以下の例で説明します。
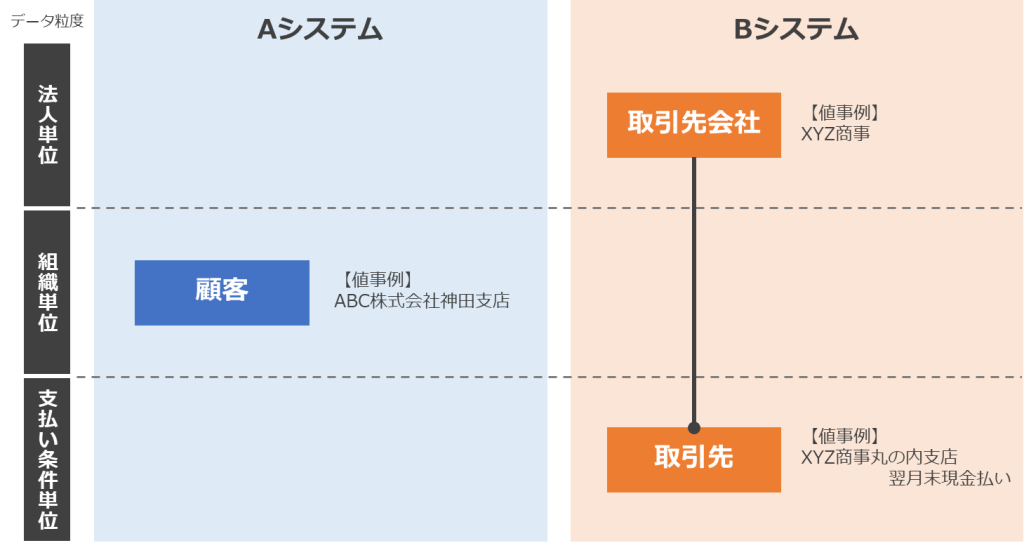
Aシステムには「顧客」テーブル、Bシステムには、「取引先」テーブルがありました。これらのテーブルの現状を調査したところ、それぞれのテーブルが管理するデータの粒度には、以下のような違いがあることが判明しました。
- Aシステムの「顧客」テーブルには、「ABC株式会社神田支店」というように、法人単位ではなくその下の支店などの組織の単位で登録されている。
- Bシステムの「取引先」テーブルには、「XYZ商事丸の内支店:手形90日サイト」「XYZ商事丸の内支店:翌月末現金払い」などの、支払い条件の単位で登録されている。また、「取引先」以外にそれらを法人単位で束ねた「取引先会社」テーブルも別途存在している。
テーブルの項目定義だけでなく、データの中身にまで一歩踏み込んだ分析を行うことがポイントです。
●ポイント2:粒度に合わせてエンティティを配置する
先ほど分析したテーブルの粒度の違いをデータモデルで表現する際、粒度の粗いエンティティを上に、粒度の細かいエンティティを下に配置するようにします。この例の場合
- Bシステムの「取引先会社」
- Aシステムの「顧客」
- Bシステムの「取引先」
が上から下に配置されます※1。
このように図の配置にひと工夫加えることで、一目で粒度の違いが明らかになり、テーブル名に惑わされず、どのテーブルが統合できるのかを関係者間でスムーズに認識を合わせることができます。
この例の場合、単純にテーブル同士を統合するのではなく、3階層で取引先を管理した方がよさそうだということが判断できます。
●補足:パッケージのデータもデータモデルで表現する
現状がパッケージシステムのため、「データ構造が分からない」「データモデルを作っていない」というケースが多くあります。
特に、パッケージの場合、本来2つの階層で管理したいデータを1階層で無理やり管理せざるを得ないため、「取引先」というテーブルでは法人は管理せず、支店や支払い条件単位を管理し、他のテーブルで法人を管理するなど、このテーブルがどのような粒度で管理されているテーブルなのかが分かりにくいことが多いように思われます。
パッケージの統廃合によりエンティティの統合や分割が必要な場合にも、粒度や配置を意識した図は現状把握に欠かせません。
実際に、筆者も異なるパッケージングシステムのテーブル統合をいくつか経験してきましたが、上記のような分かりにくさがありました。その度に、データモデルで現状のシステムがどのようにデータを管理しているのかを表現し、配置を工夫して意識合わせをすることの重要性を感じています。
●最後に
今回のブログをお読みいただき、そもそもデータモデルって何?どうやって書くの?といった疑問を持った方もいらっしゃるかもしれません。
弊社では、データモデル作成の教育コースを提供しています。
データモデルをどう作成すればよいのかについて詳しく知りたい方は是非この機会に受講してみてはいかがでしょうか。
データモデリング教育コース:
https://metafind.jp/education/data_management_academy/data_modeling/