
ビッグデータ活用のためのデータアーキテクチャを考える
ビッグデータを活用するための基盤には、従来の構造化データだけでなく、画像やテキストなどの非構造化データの管理が求められます。
また、構造化/非構造化データをバラバラに使うのではなく、お互いをひもづけ、より価値ある分析を実施できるようにしたいものです。
今回はこうした基盤にはどのような領域が必要なのか、データアーキテクチャのコンセプトについて考えてみます。
非構造化データはローデータのまま長期蓄積する
 非構造化データは社内外のさまざまな視点や粒度のデータから構成されます。
非構造化データは社内外のさまざまな視点や粒度のデータから構成されます。
主に機械学習や予測分析で使用され、分析の視点も多様です。
このようにバラバラのデータをバラバラの目的のために事前に整備しようとしても、終わりのない作業になってしまいます。
そのため、データソースから取得した非構造化データはローデータのまま長期蓄積し、活用目的に備えておきます。(下図の①)
「構造化できるデータ」はデータウェアハウスに連携する
構造化データと言うと、社内の基幹システムに由来するデータが大半です。
主に過去のビジネスの可視化/レポーティングで使われます。社内という限定された範囲のデータを特定の目的で使用するので、非構造化データに比べ統合・標準化しやすいです。
こうした特性を考慮したアーキテクチャとして
・ステージングエリア:ソースデータの標準化
・データウェアハウス(以下DW):標準化済データの長期蓄積
・データマート:目的に合致するDWデータの部分集合
の3つの領域がよく使われます。今後もこのアーキテクチャは効果的でしょう。
ところで非構造化データには、一定の規則性を持ち構造化できるデータ(下図の②)があります。(※1)こうした「構造化できるデータ」をDWに取り込めれば、既存のレポートや可視化に新しい視点を加えて、より深い分析に繋げられるでしょう。
(例 百貨店の店舗別売上(構造化データ)と顧客のGPS経路(非構造化データ)の関係の可視化)
また、「構造化できるデータ」がDWである程度標準化されていれば、機械学習のためにユーザが行う前処理作業量の削減にも繋がります。
※1たとえばGPSセンサはXMLやJSONなどの非構造化データをミリ秒単位で出力します。出力データは同じタグの組み合わせをいつも持つので、タグをカラムと捉えて、RDBMSのレコードに変換できます。
ユーザが直接処理できる領域を用意する
機械学習や予測分析ではデータを都度加工することが多いので、①のローデータやDWをユーザに直接開放してしまうと、思わぬ影響がでてしまうかもしれません。
そのためユーザ部門の処理用に、必要なデータをコピーした領域を用意します。(下図の③)
また、こうしたデータはユーザに放置されがちなので、「分析を終えたら削除する」といったルールを定めたほうがいいでしょう。
以上を整理すると、下図のようなデータアーキテクチャ図ができあがります。
今後ビッグデータ活用基盤を作る企業の方のご参考になれば幸いです。
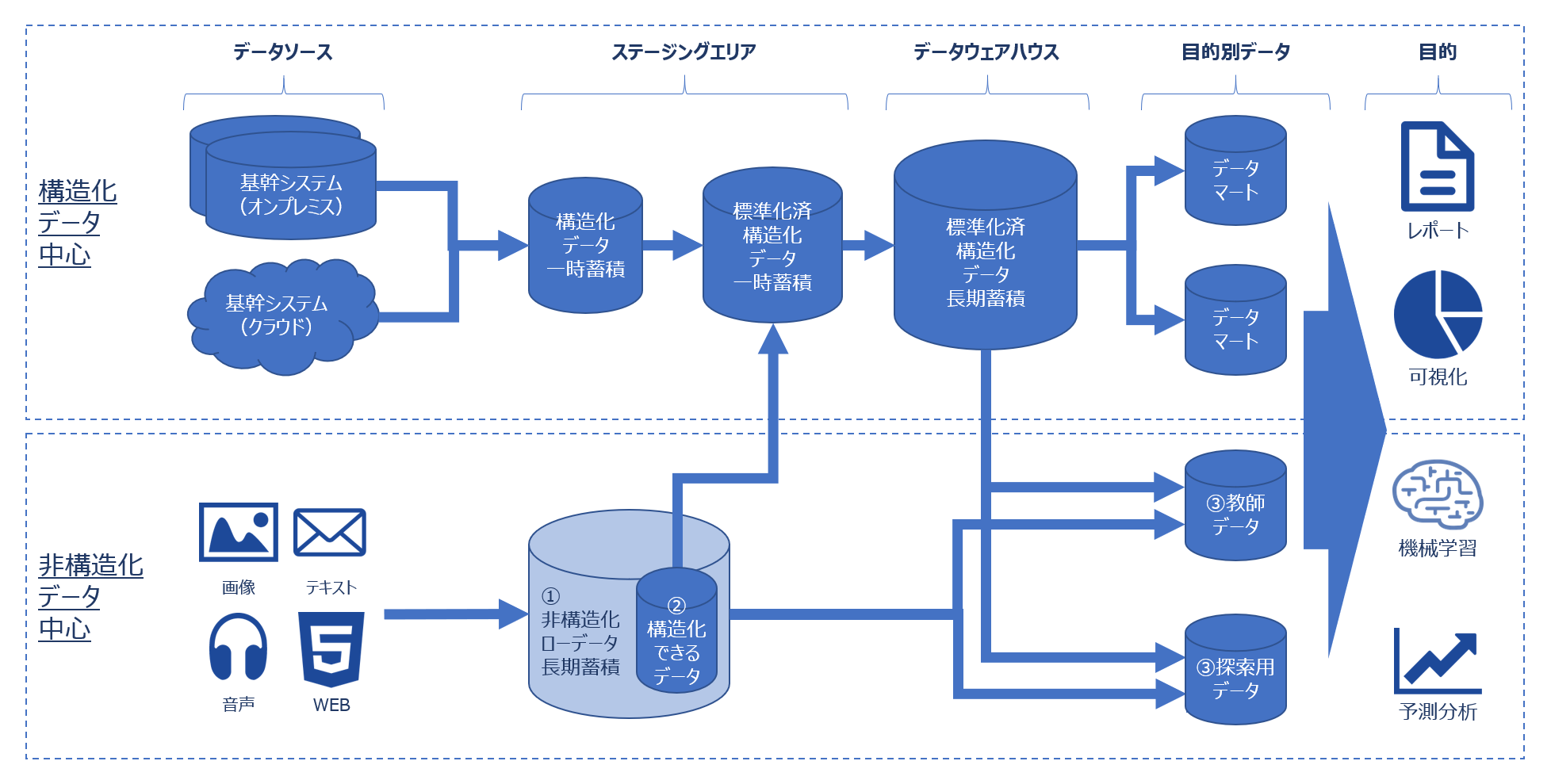
コンセプト図なので、ひとつひとつの円柱がDBMSとは限りません。
物理実装レベルでは①~③をひとつのツールで実装することもあります。

